5. 隐私计算任务操作指引(专家模式)¶
标签: 专家模式 操作指南
为了更灵活地扩充系统功能,WeDPR基于Jupyter构建了专家模式,每个注册用户均可拥有一个独立的Jupyter,并在Jupter环境中,使用WeDPR隐私计算toolkit wedpr-ml-toolkit发起各类隐私计算任务。
注解
WeDPR中,Jupyter环境采用Linux用户系统实现权限隔离,保证每个用户资源的安全性,每个docker最多可为8个用户提供Jupyter环境 若用户数目超过可部署的Jupyter数目,系统将无法为新增用户提供Jupyter环境,需要扩容新的Jupyter Docker容器来支撑更多用户
5.1 打开专家模式项目¶
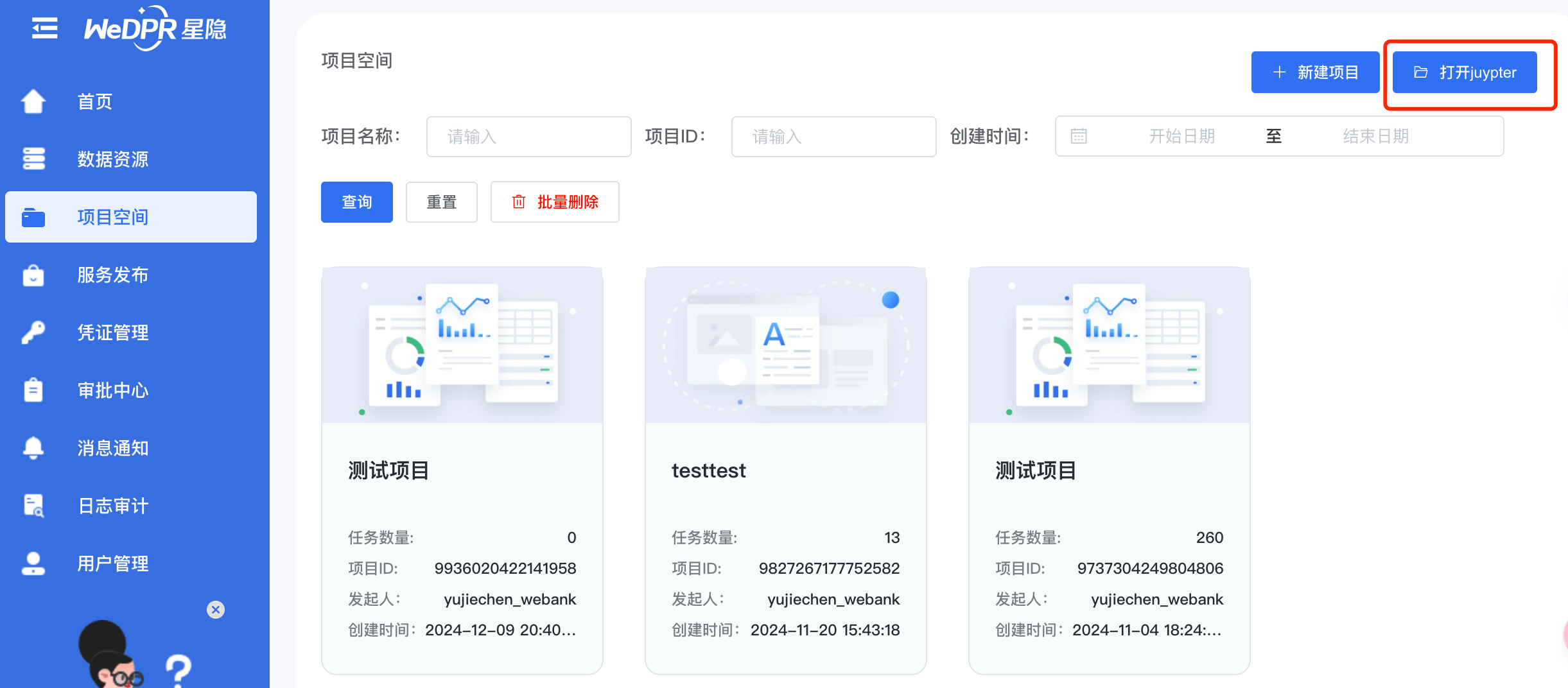
单击左侧导航栏的【项目空间】,进入到项目页面,单击右上角的【打开jupyter】按钮可打开该用户的专家模式项目空间:
注解
若Jupyter项目打开失败,请联系系统管理员,确认是Jupyter分配失败还是Jupyter容器出现异常。
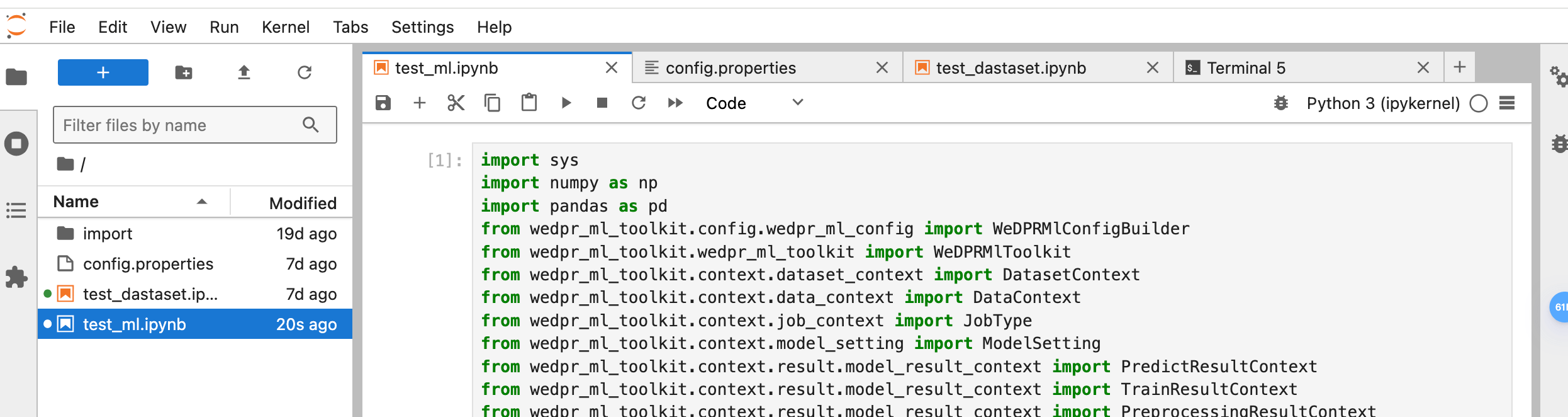
专家模式ui界面如下:
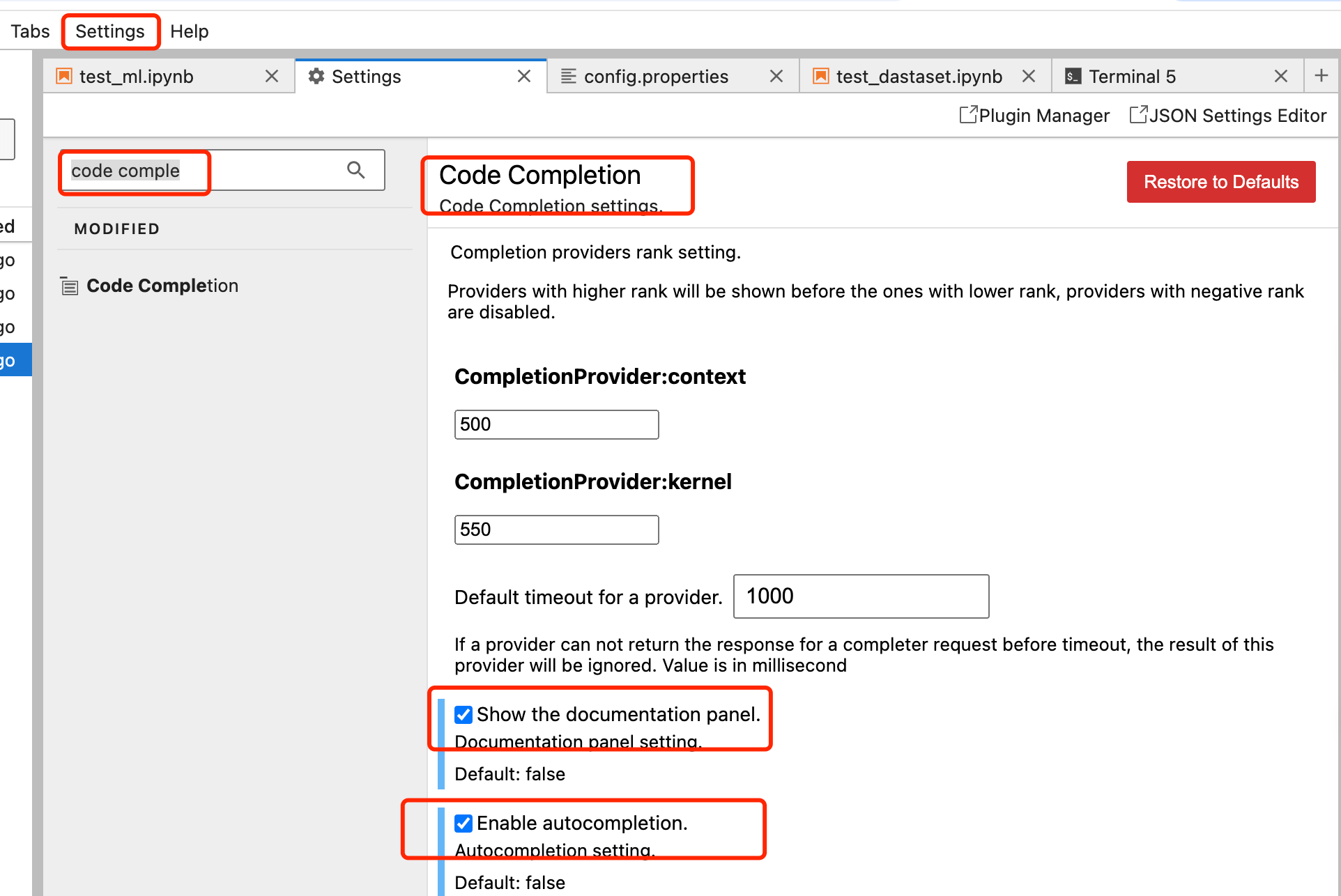
为了方便在Jupyter中开发,可单击菜单栏的【Settings】,选择【Settings Editor】选项,并在弹出的页面中搜索【code completion】,设置代码自动补全,如下:
5.2 专家模式发起任务¶
专家模式下,可使用专家模式sdk发起隐私计算任务。本节以为Demo的形式,简单介绍该SDK的使用方式。
注解
专家模式的完整代码Demo可参考 这里
5.2.1 配置隐私计算平台信息¶
前置条件
参考访问凭证章节申请并启用了访问凭证
须知隐私计算平台的基本信息,包括:访问入口,机构名,工作空间路径,HDFS WebFS访问URL等s
配置隐私平台信息
在左侧的菜单栏,单击右键,在弹出的下拉框中选择【New File】, 创建一个文件,并将其命名为config.properties, 双击该配置文件,向其中填充如下内容:
access_key_id=
access_key_secret=
remote_entrypoints=http://127.0.0.1:8010
# remote_entrypoints=http://127.0.0.1:8010,http://127.0.0.1:8011
agency_name=agency0
workspace_path=/user/wedpr/agency0
user=alice_agency0
storage_endpoint=http://127.0.0.1:50070
enable_krb5_auth=false
access_key_id: 访问凭证的ID,用于生成访问隐私计算平台API的签名access_key_secret: 访问凭证的私钥,用于生成访问隐私计算平台APId的签名remote_entrypoints: 隐私平台访问urlagency_name: 当前用户所属机构(请根据实际情况配置)user: 当前用户名(请根据实际情况配置)storage_endpoint: HDFS访问url(请根据实际情况配置)enable_krb5_auth: HDFS权限认证,默认为false
若隐私计算平台使用的HDFS开启了权限认证,则需要添加如下配置:
hdfs_auth_principal=
hdfs_auth_password=
hdfs_hostname_override=
hdfs_auth_principal: 用户访问HDFS的认证主体名hdfs_auth_password: 用户访问HDFS的扣龙hdfs_hostname_override: HDFS信任的域名,一般可不配置
5.2.2 创建Note Demo¶
在Jupyter左侧菜单栏右击,在弹出的列表框中选择【New NoteBook】,选择【Python3(ipykernel)】,创建一个新的Jupyter notebook
选中上步创建的notebook 【Untitled.ipynb】, 右击,在弹出的列表框中选择【Rename】,将其重命名为【Demo.ipynb】
5.2.3 初始化专家模式SDK¶
配置config.properties且创建了笔记本Demo.ipynb后,可通过如下代码初始化专家模式SDK:
import sys
import numpy as np
import pandas as pd
from wedpr_ml_toolkit.config.wedpr_ml_config import WeDPRMlConfigBuilder
from wedpr_ml_toolkit.wedpr_ml_toolkit import WeDPRMlToolkit
from wedpr_ml_toolkit.context.dataset_context import DatasetContext
from wedpr_ml_toolkit.context.data_context import DataContext
from wedpr_ml_toolkit.context.job_context import JobType
from wedpr_ml_toolkit.context.model_setting import ModelSetting
from wedpr_ml_toolkit.context.result.model_result_context import PredictResultContext
from wedpr_ml_toolkit.context.result.model_result_context import TrainResultContext
from wedpr_ml_toolkit.context.result.model_result_context import PreprocessingResultContext
from wedpr_ml_toolkit.config.wedpr_ml_config import WeDPRMlConfigBuilder
from wedpr_ml_toolkit.wedpr_ml_toolkit import WeDPRMlToolkit
# 读取配置文件,加载配置
wedpr_config = WeDPRMlConfigBuilder.build_from_properties_file('config.properties')
# 加载专家模式SDK
wedpr_ml_toolkit = WeDPRMlToolkit(wedpr_config)
5.2.4 数据集相关操作¶
数据集操作均围绕DatasetMeta, DatasetContext,前者数据集的元信息的抽象,后者存储了数据集操作的上下文信息。
专家模式既支持数据开发人员产生新的数据集;也支持更新已存在的数据集内容。
可通过专家模式SDK构建并保存新的数据集到HDFS中(Note: 这里权限隔离,数据文件仅保存在配置用户家目录),方便数据开发人员暂存一些临时数据:
# 随机构造数据
df = pd.DataFrame({
'id': np.arange(0, 100), # id列,顺序整数
'y': np.random.randint(0, 2, size=100),
# x1到x10列,随机数
**{f't{i}': np.random.rand(100) for i in range(1, 11)}
})
# 设置数据集的meta信息
dataset1_meta = DatasetMeta(file_path = "d-01", user_config = wedpr_config.user_config)
# 基于元数据信息构建DatasetContext
dataset1 = DatasetContext(storage_entrypoint=wedpr_ml_toolkit.get_storage_entry_point(),
storage_workspace=wedpr_config.user_config.get_workspace_path(),
dataset_meta = dataset1_meta)
print(f"* dataset1: {dataset1.dataset_meta}")
# 将构造的数据写入到元数据定义的数据集中
dataset1.save_values(df)
print(f"* updated dataset1: {dataset1}")
# 加载数据
(values, cols, shape) = dataset1.load_values()
print(f"* load values result: {cols}, {shape}, {values}")
专家模式SDK也支持修改HDFS已存在的数据集内容,方便数据开发人员对已经存在的数据集进行清洗、预处理等:s
注解
用户仅可更新自己的数据集,无权限更新其他用户的数据集
from wedpr_ml_toolkit.context.dataset_context import DatasetContext
from wedpr_ml_toolkit.transport.wedpr_remote_dataset_client import DatasetMeta
# 创建数据集context(Note: 这里仅可选择当前用户的自己数据集)
dataset_id = "d-9866227816474629"
dataset2 = DatasetContext(storage_entrypoint=wedpr_ml_toolkit.get_storage_entry_point(),
dataset_client=wedpr_ml_toolkit.dataset_client,
storage_workspace=wedpr_config.user_config.get_workspace_path(),
dataset_id = dataset_id)
print(f"* dataset2 meta: {dataset2}")
# load values
# 读取数据集信息
(values, cols, shape) = dataset2.load_values(header=0)
print(f"* dataset2 detail, cols: {cols}, shape: {shape}, values: {values}")
# 随机构建数据
df2 = pd.DataFrame({
'id': np.arange(0, 100), # id列,顺序整数
**{f'w{i}': np.random.rand(100) for i in range(1, 11)} # x1到x10列,随机数
})
# 使用新生成的数据更新数据集信息
dataset2.save_values(values=df2)
print(f"*** updated dataset2 meta: {dataset2}")
# 加载更新后的数据集信息
(values, cols, shape) = dataset2.load_values(header=0)
print(f"*** updated dataset2 detail, cols: {cols}, shape: {shape}, values: {values}")
5.2.5 构建隐私计算任务所需的多方数据集¶
发起隐私计算任务前,需加载相关方的数据集信息。
加载机构agency0当前登录用户的数据集(这里也更新了该数据集内容):
# 实际操作时,请替换成您自己的数据集ID
dataset_id = 'd-9743660607744005'
# - storage_entrypoint: 用于连接HDFS client实例
# - dataset_client: 用于获取数据集信息的client实例
# - dataset_id: 用于联合建模的数据集id
# - is_label_holder: 是否是标签y的提供方
dataset1 = DatasetContext(storage_entrypoint=wedpr_ml_toolkit.get_storage_entry_point(),
dataset_client=wedpr_ml_toolkit.dataset_client,
dataset_id = dataset_id,
is_label_holder=True)
print(f"* load dataset1: {dataset1}")
(values, cols, shapes) = dataset1.load_values()
print(f"* dataset1 detail: {cols}, {shapes}")
print(f"* dataset1 value: {values}")
# 更新数据集信息
data_size = 100000
feature_num = 200
df = pd.DataFrame({
'id': np.arange(0, data_size), # id列,顺序整数
'y': np.random.randint(0, 2, size=data_size),
# t1到tx列,随机数
**{f't{i}': np.random.rand(data_size) for i in range(1, feature_num)}
})
dataset1.save_values(df)
print(f"* updated dataset1: {dataset1}")
加载agency1数据集信息:
# 实际操作时,请替换成需要参与联合建模的的数据集ID
dataset_id = "d-9743674298214405"
dataset2 = DatasetContext(storage_entrypoint=wedpr_ml_toolkit.get_storage_entry_point(),
dataset_client = wedpr_ml_toolkit.dataset_client,
dataset_id = dataset_id)
print(f"* dataset2: {dataset2}")
构建多方数据集的上下文信息:
multi_data_ctx = DataContext(dataset1, dataset2)
5.2.6 发起隐私计算任务¶
基于上节构建的multi_data_ctx可发起数据预处理、SecureLGBM训练、SecureLGBM预测等任务,并获取任务执行结果。
定义任务执行的项目ID
# 实际操作时,请从【项目空间】中选择您自己的项目ID
project_id = "9737304249804806"
SecureLGBM训练任务
构建SecureLGBM训练任务的上下文信息:
# 创建训练参数对象
model_setting = ModelSetting()
# 训练任务使用PSI先对多方数据求交集
model_setting.use_psi = True
# 构建SecureLGBM训练任务上下文
# - job_type: 任务类型,设置为JobType.XGB_TRAINING
# - project_id: 运行任务的项目ID
# - dataset: 任务关联的多方数据集上下文
# - model_setting: 算法参数
xgb_job_context = wedpr_ml_toolkit.build_job_context(
job_type = JobType.XGB_TRAINING,
project_id = project_id,
dataset = multi_data_ctx,
model_setting = model_setting)
print(f"* build xgb job context: {xgb_job_context}")
提交SecureLGBM训练任务:
# 执行SecureLGBM训练任务
xgb_job_id = xgb_job_context.submit()
print(xgb_job_id)
获取SecureLGBM训练任务执行结果:
print(xgb_job_id)
# 第二个参数为True表明阻塞等待任务执行完毕;为False表明不阻塞等待任务执行完毕
xgb_result_detail = xgb_job_context.fetch_job_result(xgb_job_id, True)
基于SecureLGBM训练任务执行结果获取上下文对象,并输出建模结果、预处理信息、效果评估、特征重要性信息等:
# 基于任务执行结果构建结果的上下文
xgb_result_context = wedpr_ml_toolkit.build_result_context(job_context=xgb_job_context,
job_result_detail=xgb_result_detail)
print(f"* xgb job result ctx: {xgb_result_context}")
# 获取测试集的训练结果
xgb_test_dataset = xgb_result_context.test_result_dataset
print(f"* xgb_test_dataset: {xgb_test_dataset}, file_path: {xgb_test_dataset.dataset_meta.file_path}")
(data, cols, shapes) = xgb_test_dataset.load_values()
print(f"* test dataset detail, columns: {cols}, shape: {shapes}, value: {data}")
# 获取效果评估信息evaluation result
result_context: TrainResultContext = xgb_result_context
evaluation_result_dataset = result_context.evaluation_dataset
(eval_data, cols, shape) = evaluation_result_dataset.load_values(header=0)
print(f"* evaluation detail, col: {cols}, shape: {shape}, eval_data: {eval_data}")
# 获取特征重要性信息 feature importance
feature_importance_dataset = result_context.feature_importance_dataset
(feature_importance_data, cols, shape) = feature_importance_dataset.load_values()
print(f"* feature_importance detail, col: {cols}, shape: {shape}, feature_importance_data: {feature_importance_data}")
# 获取预处理结果
preprocessing_dataset = result_context.preprocessing_dataset
(preprocessing_data, cols, shape) = preprocessing_dataset.load_values()
print(f"* preprocessing detail, col: {cols}, shape: {shape}, preprocessing_data: {preprocessing_data}")
# 获取建模结果:
model_result_dataset = result_context.model_result_dataset
(model_result, cols, shape) = model_result_dataset.load_values()
print(f"* model_result detail, col: {cols}, shape: {shape}, model_result: {model_result}")
加载建模结果,绘制ROC/PR曲线:
# 明文处理预测结果
from sklearn.metrics import roc_curve, roc_auc_score, precision_recall_curve, accuracy_score, f1_score, precision_score, recall_score
import matplotlib.pyplot as plt
(data, cols, shapes) = result_context.model_result_dataset.load_values(header = 0)
# 提取真实标签和预测概率
y_true = data['class_label']
y_pred_proba = data['class_pred']
y_pred = np.where(y_pred_proba >= 0.5, 1, 0) # 二分类阈值设为0.5
# 计算评估指标
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
auc = roc_auc_score(y_true, y_pred_proba)
print(f"Accuracy: {accuracy:.2f}")
print(f"Precision: {precision:.2f}")
print(f"Recall: {recall:.2f}")
print(f"F1 Score: {f1:.2f}")
print(f"AUC: {auc:.2f}")
# ROC 曲线
fpr, tpr, _ = roc_curve(y_true, y_pred_proba)
plt.figure(figsize=(12, 5))
# ROC 曲线
plt.subplot(1, 2, 1)
plt.plot(fpr, tpr, label=f'AUC = {auc:.2f}')
plt.plot([0, 1], [0, 1], 'k--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend()
# 精确率-召回率曲线
precision_vals, recall_vals, _ = precision_recall_curve(y_true, y_pred_proba)
plt.subplot(1, 2, 2)
plt.plot(recall_vals, precision_vals)
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.tight_layout()
plt.show()
SecureLGBM预测任务
构造SecureLGBM预测任务
# 构造xgb预测任务配置,并设置use_psi为True
# (由于两方数据量规模不一定一样,推荐在建模之前先运行PSI算法)
predict_setting = ModelSetting()
predict_setting.use_psi = True
# - job_type: 任务类型,这里设置为JobType.XGB_PREDICTING
# - project_id: 用于发起任务的项目ID
# - model
predict_xgb_job_context = wedpr_ml_toolkit.build_job_context(
job_type=JobType.XGB_PREDICTING,
project_id = project_id,
dataset= multi_data_ctx,
model_setting= predict_setting,
predict_algorithm = xgb_result_context.job_result_detail.model_predict_algorithm)
print(f"* predict_xgb_job_context: {predict_xgb_job_context}")
提交SecureLGBM预测任务
# 提交xgb预测任务
xgb_predict_job_id = predict_xgb_job_context.submit()
print(xgb_predict_job_id)
获取SecureLGBM任务执行结果:
# query the job detail
print(f"* xgb_predict_job_id: {xgb_predict_job_id}")
predict_xgb_job_result = predict_xgb_job_context.fetch_job_result(xgb_predict_job_id, True)
基于SecureLGBM任务执行结果构建上下文信息:
# generate the result context
result_context = wedpr_ml_toolkit.build_result_context(job_context=predict_xgb_job_context,
job_result_detail=predict_xgb_job_result)
xgb_predict_result_context : PredictResultContext = result_context
print(f"* result_context is {xgb_predict_result_context}")
基于SecureLGBM预测结果绘制评估曲线:
# 明文处理预测结果
from sklearn.metrics import roc_curve, roc_auc_score, precision_recall_curve, accuracy_score, f1_score, precision_score, recall_score
import matplotlib.pyplot as plt
(data, cols, shapes) = xgb_predict_result_context.model_result_dataset.load_values(header = 0)
# 提取真实标签和预测概率
y_true = data['class_label']
y_pred_proba = data['class_pred']
y_pred = np.where(y_pred_proba >= 0.5, 1, 0) # 二分类阈值设为0.5
# 计算评估指标
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
auc = roc_auc_score(y_true, y_pred_proba)
print(f"Accuracy: {accuracy:.2f}")
print(f"Precision: {precision:.2f}")
print(f"Recall: {recall:.2f}")
print(f"F1 Score: {f1:.2f}")
print(f"AUC: {auc:.2f}")
# ROC 曲线
fpr, tpr, _ = roc_curve(y_true, y_pred_proba)
plt.figure(figsize=(12, 5))
# ROC 曲线
plt.subplot(1, 2, 1)
plt.plot(fpr, tpr, label=f'AUC = {auc:.2f}')
plt.plot([0, 1], [0, 1], 'k--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend()
# 精确率-召回率曲线
precision_vals, recall_vals, _ = precision_recall_curve(y_true, y_pred_proba)
plt.subplot(1, 2, 2)
plt.plot(recall_vals, precision_vals)
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.tight_layout()
plt.show()